Securing your Hadoop Cluster: Step 1: User Authentication

I will publish articles narrating our experience and how to implement security on the Hadoop cluster. In this first article of the series, let’s see how to resolve the user authentication challenge in Hadoop.
Importance of Big Data Security
The amount of data being generated in enterprises is proliferating. Big Data technologies help organizations to capture, analyze, and manage this ever-increasing data. With this great power comes the responsibility of keeping business-critical data safe and secure.
Above all, Our team of Big Data experts at Ellicium has done extensive work securing complex and large Hadoop infrastructure. In one such case, we are helping our client in the finance domain with Big Data Managed services, where Hadoop security is one of the major areas we focus on.
Here, we have secured a Hadoop cluster with more than 60+ servers/nodes that host sensitive financial data. This cluster was built using Hortonworks Distribution Hadoop (HDP version 2.6.0.1). The cluster runs diverse services like HDFS, YARN, MR2, Tez, Zookeeper, Hive, Spark2, HBase, Phoenix, Kafka, Ambari Metrics, and Ranger.
Moreover, securing this Hadoop cluster took a lot of work, as it was essential to ensure it without altering much of the existing workflow. However, we have come up with a series of steps that will make the task of securing your Hadoop cluster based on the collective experience of Ellicians,
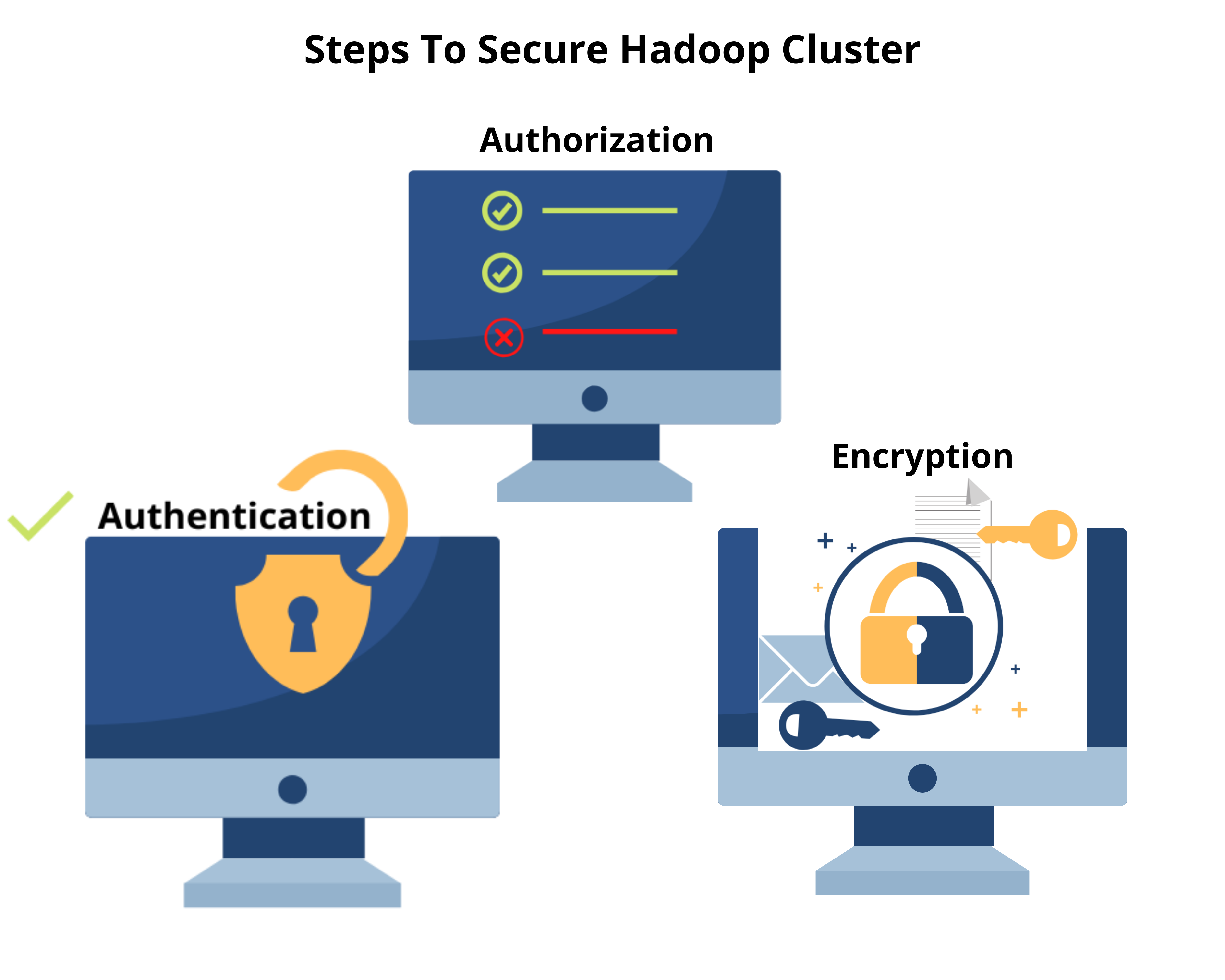
Steps to secure Hadoop Cluster
- User authentication
- User authorization
- Encryption
As stated in this article’s beginning, let’s see how to resolve the user authentication challenge in Hadoop.
What is Authentication?
Authentication is a process in which a user is verified as an authentic user using the provided credentials. Authentication is important because it enables organizations to keep their networks secure by permitting only authenticated users to access its protected resources/services.
Lack of user authenticity in Hadoop
By default, Hadoop does not have a strong authentication mechanism, so a user can pretend to be authentic and gain access to the cluster, exploiting security and accessing unauthorized data. This is a significant risk and prevents organizations from adopting Hadoop.
In our case, we were using services like Phoenix and Hive. These are inherently insecure services, as, by default, they do not have any mechanism to verify the authenticity of the users. We used Kerberos to secure these services in Hadoop. Though it can be done in multiple ways, other methods are unsafe; thus, it can not be recommended.
How to implement strong authentication in Hadoop?
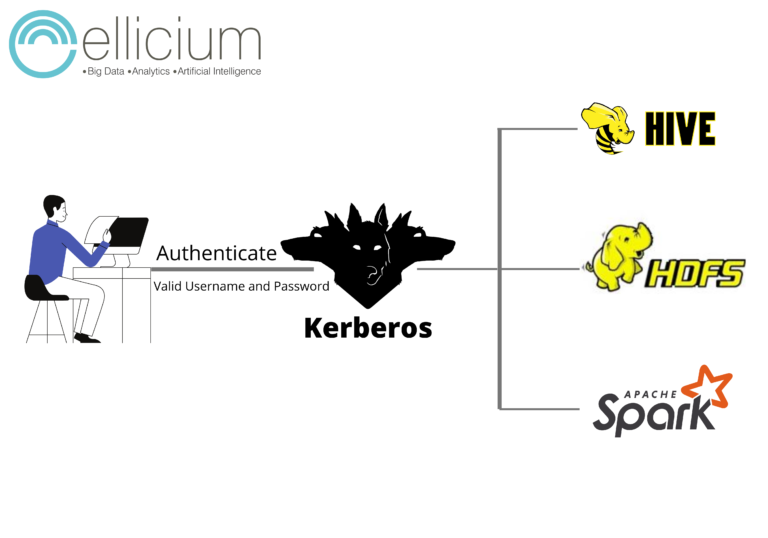
Kerberos is an authentication protocol that allows the system to verify user authenticity using tokens over secured and unsecured networks. However, by implementing Kerberos, you can make it mandatory for users to prove their identity. Thus preventing authorization access against impersonating users.
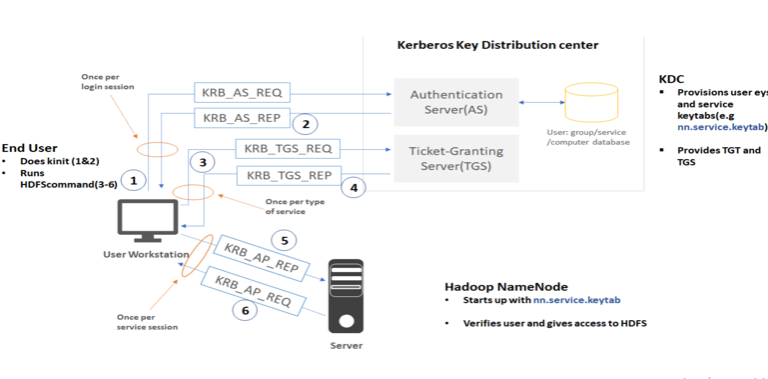
The steps in Kerberos exchanges diagram are in detail below:
- Client requests to KDC for TGT (ticket-granting ticket) using its principal name.
- In response, AS (authentication server) issues a TGT (ticket-granting ticket) and a session key, which the client can use to encrypt and authenticate communication between the KDC for TGT requests.
- Once TGT has obtained further, clients can request a ticket from TGS (Ticket Granting Server).
- TGS provides a ticket to the client, which gets stored on the client’s workstation.
- Whenever a client requests an application program, the cached ticket is in use to verify client authenticity.
- After the client’s authenticity has been verified, the client can continue to use the service.
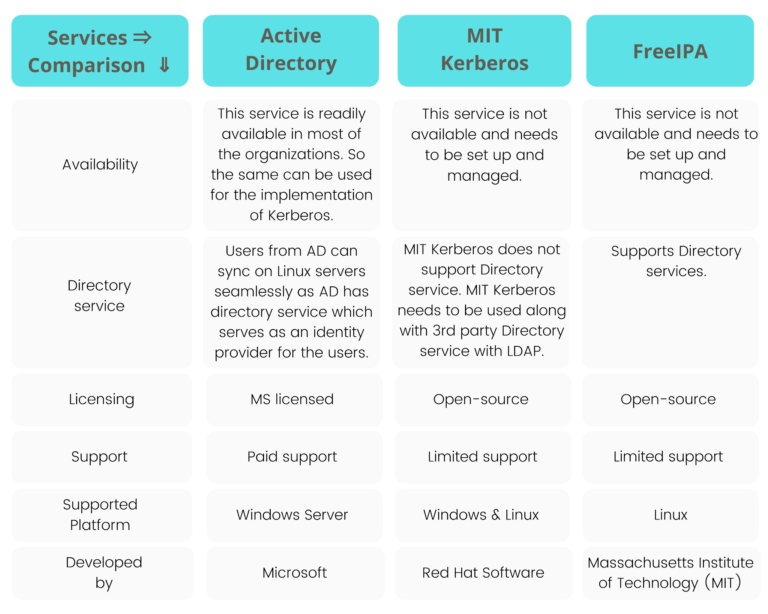
In a Hadoop cluster, Kerberos can be implemented using MIT Kerberos, Active Directory, or FreeIPA server. We recommend that the group get secure using the Enterprise Active Directory server, considering the brief comparison between Active Directory, MIT Kerberos, and FreeIPA.
Why do we recommend the Enterprise Active Directory server? Check this brief comparison with other services.
Once the cluster is Kerberized and integrated with Active Directory or FreeIPA using LDAP (Lightweight Directory Access Protocol), users can log in to Gateway nodes/servers using their domain user ID and cache the tickets using the init command. However, the job will fail with GSSException if users try to use any Hadoop services without caching the keys, as below:

The token is a must for the execution of jobs in a Kerberized cluster environment.
Brief description of the Kinit command
Moreover, Kinit is to obtain and cache Kerberos ticket-granting tickets.
Syntax : knit @
Once the user executes this command, they will get a prompt for a password, and after entering the valid password, the ticket will be cached.
Below is an example, in addition, that shows you the Kinit command that can be use to cache tickets on a Linux server through CLI:

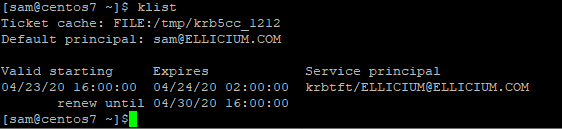
Similarly, we have klist and kdestroy commands.
Klist command: To view the Kerberos cached ticket.
Syntax: list
Kdestroy command: Destroys a Kerberos credentials cache.
Syntax: destroy

For automated applications/jobs, users can generate and use keys. A key is a file containing pairs of Kerberos principals and encrypted keys. This can be developed and stored on the gateway nodes and used to cache the token without any manual inputs.
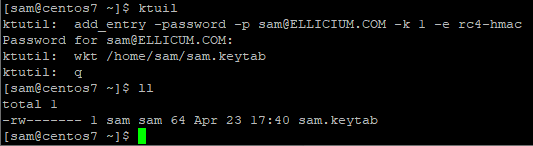
Below is an example of how to generate a keytab file on a Linux machine using the ktutil command when Kerberos integrates with Active Directory server:
Below is an example of how to pass the principal(username with realm) and keytab file to an automated spark application:
![]()
Conclusion
In short, implementing Kerberos provides robust security features and protects the system from attacks. In the following article, I will share about User authorization. Also, how to implement it to strengthen Hadoop security further.